The McGurk effect is a perception illusion, which shows how our perception of reality can be affected by interactions between multiple senses. The presentation of the McGurk effect demonstrated in the following video also shows, convincingly, that our visual processes can completely override our auditory perceptions of speech — at least in certain circumstances.
In the above video, you will see the speaker's lips form an 'f'-sound. You will “hear” an 'f'-sound even though the actual sound being produced is a 'b'-sound (dubbed in over the video).
In this video, the 'f' perception reported by your eyes completely overrides the 'b' perception reported by your ears. Can we conclude, from this, that visual processing in the brain is given full priority over auditory processing?
That may be a bit hasty.
The easy explanation for what is seen in the video, is that the brain intrinsically favors visual processes over auditory processes. Is that really what's happening here? Watch the video again, but this time, carefully observe the sequence and timing between the visual 'f' cues, and the first production of audio. Notice the delay.
The speaker clearly sets up his teeth and lips to produce the 'f'-sound, pauses for a short time (100-200 ms?), and only then does the pre-recorded 'b'-sound begin. In other words, there is a deliberate pause, after setting up the visual 'f' cues, before providing the 'b'-sound. The pause is long enough so that you are able to fully perceive the 'f'-sound you
see, before the audio of the dubbed in 'b'-sound begins.
Here's another youtube video that is a short set of edits from the above video. It includes a scene in the beginning that is not properly synchronized. This serendipitously helps to demonstrate the point.
http://www.youtube.com/watch?v=MeWoqkOvd1Y
Because of the synchronization issues in the early part of the linked video, you are able to experience this effect with the curtain pulled back a bit. Here, the audio is emitting earlier with respect to the visual. There is a much shorter delay between the time you perceive what sound his mouth will make, and the hearing of the dubbed-in 'b'-sound.
The slight changes in timing help to clarify what's happening. The fact that the visual processing of the 'f'-sound was given ample time to complete
before the audio stimuli began seems to have played a central role in the illusion.
Now we can see that the perception of the sound as an 'f' is likely to have been more a function of the sequence and temporality of the arriving stimuli. The effect is not
necessarily caused by any innate precedence of visual brain-function over audio brain function.
[1] 
The time it takes to fully perceive the 'f'-sound that Professor Rosenblum's
[2] lips and teeth are forming in the video, seems to be the time in which the
neural network is
converging on a given explanation for the incoming stimuli-stream. By the time the audio finally begins, the neural network has already fully converged
[3] and stabilized on the 'f' representation. This was, in fact, the correct representation for the stream of stimuli experienced up to that point.
Unlike our conventional mathematical models, biological neural networks do not have the luxury of operating outside of the linear flow of time. They must function in real-time, and therefore, they commit, as soon as they can, to what is normally a fairly reliable perception of reality. This tendency to commit to a given perception can be seen in single-mode interpretations too; for example, when we see a wire-drawing of a 3-D cube.
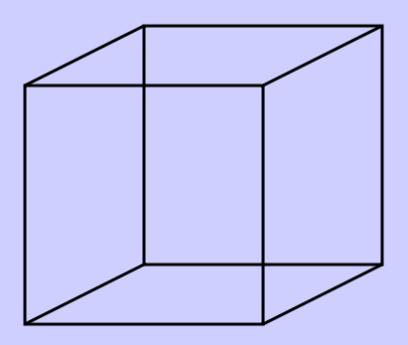
In the above cube, the three dimensional interpretation is ambiguous, but the neural network will converge on one or the other of the two possibilities. There is always reactive convergence, representing a commitment to a given interpretation, but it can be flipped between the two interpretations.
The cube is perfectly ambiguous between the two choices, and in that respect it is not a perfect analogy for the video. The perception provided by your brain while watching the video is very consistent with reality. The video itself, on the other hand, is an artificially produced simulation that has been deliberately made inconsistent with reality. That is, it was constructed by dubbing in a new sound over the existing “real” sound that was originally made.
In this case, the flow of time (or, perhaps, more correctly, the flow of events in time) is a primary contributing factor. If the two stimuli—audio and visual—could be moved back and forth relative to each other over a smooth scale, the insights gained from the improperly synchronized video could be expanded. One might find a place on that scale where the sound that is perceived is a combination of the two sounds. At some point, as the two are moved farther apart we may observe that the effect fully diminishes. The diminishing of the effect with a long enough period between them would likely happen in both directions. Would the period be symmetrical for both directions?
Also, perhaps, at some stationary point along the synchronization continuum, the sound would seem to flip back and forth between the two perceptions. This would be similar to how a wire-drawing of a cube can be interpreted to be in one of two different 3-D configurations (see above).
What is needed, to answer these questions, is a system that lets you smoothly move the audio back and forth in time relative to the visual.
- Related Background
- Related Blog Entries
- Dance and Sound
What if perceptions of words are very tightly linked to the formation of cross-modal, metaphorical, relationships that include body movements and the physical constraints of three-dimensional motion. Just speculating, really.
- Multitemporal Synapses and Our Perception of a Present Moment
A theory of learning and connection formation that explains and predicts our perception of a present moment in time.
- Introducing: Multitemporal Synapses
An earlier introduction to the subject matter of the above entry.
- All the Words a Metaphor
The notion that words may be metaphorically linked to physical movements and motions is an idea I sometimes entertain. Certainly, it seems to be supported by the McGurk effect.
- Red Sky in Morning - Temporality, Sequence, and Causality
Apparent sequential precedence is sometimes misleading.
- Syntax not in Broca's Area?
There's more to it than visual processing, especially at the higher levels.
- Netlab's Compatibility Mode
Netlab tries to let those who are used to working with conventional, mathematical based models feel as comfortable as possible.
- Synaesthesia: not a mental anomaly, a mental characteristic
At the higher levels, modes cross and combine in interesting ways. This blog entry links a very interesting discussion by V. S. Ramachandran, of the idea that there is, at least, a bit of synestheasia in all of us.
* Thanks to James Taylor, for finding this.
[1] — That doesn't mean there isn't intrinsic favoritism given to visual processes, only that, in spite of first impressions, this experiment doesn't really show it.
[2] — Professor
Lawrence Rosenblum, University of California, Riverside.
[3] — This is not the conventional
adaptive convergence seen, for example, when a traditional feedforward neural network is being trained on a set of exemplars. Nor is it the adaptive convergence that occurs when multitemporal synapses are relearning in-the-moment responses to the present moment. This sense of the word does not involve changes to connection-strengths at all. Here, we are discussing
reactive convergence of propagated signals representing only stimuli (not changes in connection strengths). When networks are configured to include signal feedback, oscillation is the norm. A trained network will (eventually) stabilize on a given steady state representation, but unlike adaptive (conventional) convergence, none of it requires changes to weight values. The convergence is based solely on the normal oscillations of a network with feedback settling down and becoming more stable and steady around a set of responses.
 Stand Out Publishing
Stand Out Publishing